
Attributive und variable Daten
Attributive und variable Daten
Bei Six Sigma Projekten und den damit verbundenen statistischen Auswertungen sollen basierend auf den vorhandenen Daten, Aussagen über Prozessfähigkeiten und kritische Prozess-Inputs getroffen werden. Für die Auswahl der richtigen grafischen und statistischen Werkzeuge muss klar sein, welche Art von Daten zugrunde liegt.
Die Daten können in folgende Untergruppen eingeteilt werden:
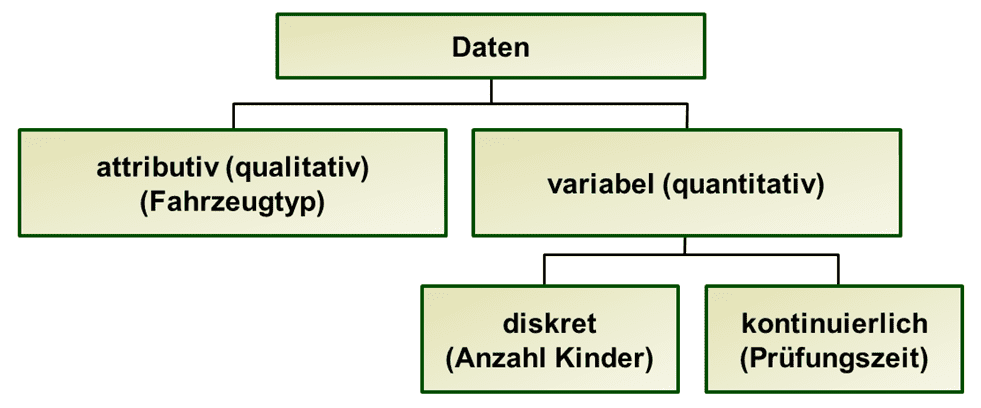
Attributive Daten
Attributive / qualitative Daten lassen sich in verschiedene Kategorien einteilen. Dabei können Eigenschaften eines Prozesses, Produkts oder Merkmales beschrieben werden. Bei jeder Kategorie lässt sich zählen, wie oft sie vorkommt.
Beispiele für mögliche Kategorien sind:
• Fehlerklassen
• gut / schlecht
• Maschine 1, Maschine 2, Maschine 3
• Verschiedene Standorte
• Frühschicht, Spätschicht
Einen Hinweis, ob es sich um attributive Daten handelt oder nicht findet man darin, ob mathematische Operationen mit den Rohdaten durchgeführt werden können. Handelt es sich um attributive Daten ergeben mathematische Operationen keinen Sinn.
Variable Daten
Variable Daten unterteilen sich noch in diskrete Daten und kontinuierliche Daten
Diskrete Daten
Diskrete Daten sind Ergebnisse von Zählungen, damit also ganzzahlige Daten.
Beispiele für diskrete Daten sind:
• Anzahl Maschinenausfälle pro Monat
• Anzahl fehlerhafte Rechnungen pro Woche
• Anzahl Kundenreklamationen
• Anzahl durchgeführter Operationen
Kontinuierliche Daten
Kontinuierliche Daten sind Messwerte, sie können einen beliebigen numerischen Wert annehmen. Eine dezimale Unterteilung ist beliebig möglich.
Beispiele für kontinuierliche Daten sind:
• Zeit
• Druck
• Bandgeschwindigkeit
• Kosten
• Abmessungen
Aussagekraft
Die Aussagekraft der Daten ist bei attributiven Daten nur bei sehr hohem Stichprobenumfang ausreichend. Außerdem gibt es häufig Probleme mit der Fähigkeit der attributiven Prüfungen.
Deshalb: Streben Sie immer kontinuierliche Daten an, um einen maximalen Informationsgehalt zu erreichen!
... finden Sie in der Rubrik Ausbildung und Training!
...... oder Sie rufen uns einfach an oder schreiben uns ein E-Mail. Wir helfen Ihnen gerne!